data platform series:
Five points to help you
avoid choosing the wrong
data platform solution
A key concept of the Data Platform Strategy blog post series is about strategic architecture – or in other words being conscious, deliberate, and context aware when designing data solutions.
We’ve discussed the merits of a platform strategy in a previous post, and whilst it’s clear that any organisation can benefit from such an approach (e.g., to avoid working in data siloes with fragmented toolsets, inconsistent or lack of standards, and inadequate governance) it is also a risk that organisation’s over engineer or on the flip side adopt technologies that won’t flex and scale to support evolving requirements.
In this post, I address some of the different data and AI use cases, and how to design suitable, appropriate data solutions via examples. I cover some specific vendor technologies at a high-level with further, detailed thoughts (e.g., unboxing data platforms from Azure and Databricks) to follow in subsequent posts.
the technology landscape has evolved quickly of late… This creates financially viable possibilities because adopting a data platform is no longer the gargantuan effort that it used to be
Key points you need to consider
When building technology systems, whether it’s a simple web application as part of a digital transformation, an integration layer, or a data platform it is crucial to architect your design to be fit-for-purpose.
For example, there is no use in designing a sophisticated, complex microservices or data mesh architecture (despite what vendors tell you!) that could scale like Spotify if you are a relatively simple organisation without much development capability. It is not a sensible endeavour, and one that will be costly in several ways. Conversely, a commercial off the shelf solution with lots of abstraction might not be suitable if you require significant flexibility – low code is always great until you hit an edge case where it doesn’t work, which has been my experience with services like Azure Data Factory and Power Apps.
Have you ever had to hire an extensive team of Kubernetes Engineers to support an overtly complex infrastructure layer? I wish you luck explaining that cost to the board.
The point is there are always trade-offs for any approach, so you need to be able to recognise them and work out if you can accept them in the context of your organisation. Knowing and being mindful of your own constraints is really important.
Here are some typical constraints/facets to consider in your selection:
- Internal capability: Think about the team you have today, their skills, and what this is likely to look like soon. Ask yourself if they support the new solution from the outset or with expert support. Also, don’t overlook user needs and digital literacy levels in the wider organisation.
- Budget: Data platforms often carry expensive run costs and can require expensive, specialist skillsets. Think about what build and run budget is available to you. Work through examples of different data volumes and input/output demands as your service scales.
- Use cases: You may not need all the capabilities and features of a data platform if your use case is simple analytics reporting with one or two data sources. Also consider your non-functional requirements, governance, and compliance needs. Again, this is also about user needs/research, engagement with your users – people might be doing data work in siloes that you’re unaware of.
- Technology orientation: If you are a heavily Microsoft centric organisation is it sensible to introduce a non-Microsoft technology solution? Probably not unless there is a compelling reason. You should also consider any on-going impending technical strategy with a view to obtaining alignment. There’s huge value from data, business, and technology stakeholders working together.
- Volumetrics: If your data platform is geared up for genuinely big data required when you’re in an organisation that produces a limited amount of data then you’re going to incur needless costs and complexity. This will hinder your progress and reduce adoption.
Note; These points should be considered in the context of your organisational strategy, goals, and future direction. For example, perhaps the aspiration is to pivot into becoming a data company, and your solution then needs to scale.
there is no use in designing a sophisticated, complex microservices or data mesh architecture (despite what vendors tell you!) that could scale like Spotify if you are a relatively simple organisation without much development capability.
Questions to ask yourself
Taking an example using some of the data technologies we work with at Pivotl (Azure, Databricks, and Fivetran), I’ve created an example decision matrix to guide the optimal selection based on answering a series of questions about your situation.
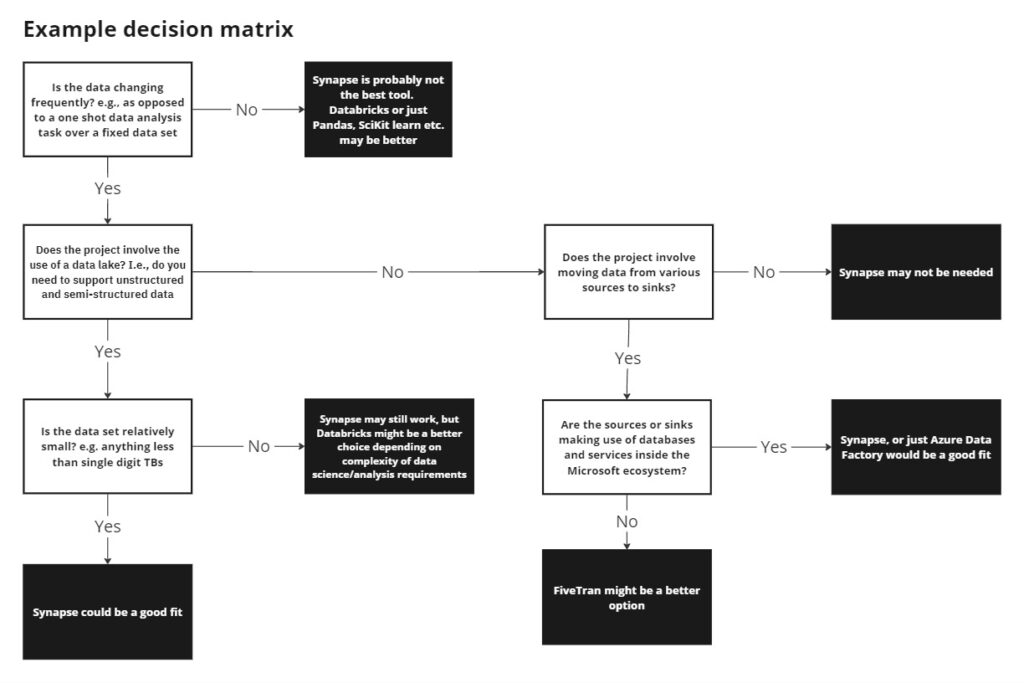
Clearly, there are a lot more questions that should be asked and where the technologies mentioned are strong/weak is subject to debate, but I wanted to give you an idea of the type of thought process that could be useful or to inspire you to create your own version.
Examples of supporting different use cases
I wanted to demonstrate how the same data platform, in this case Azure, can be configured to support different use cases and organisational needs.
This example shows a relatively simple analytics set up.
In contrast, the following example shows a more data science oriented set up.
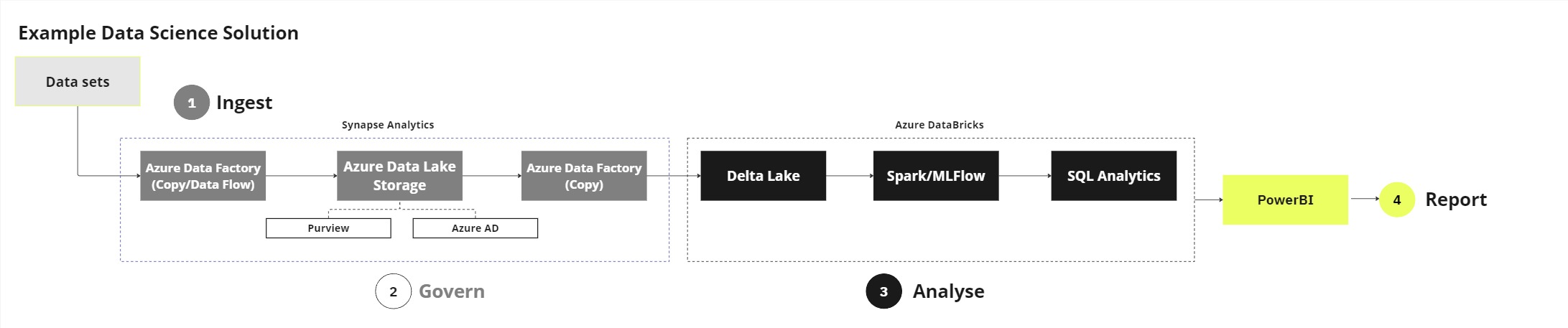
one thing I emphasise when selecting architecture is the need to run technical spike as part of an evaluation process.
Where solutions fall on the curve of complexity
Now, bringing this back to the data platform strategy theme of blog posts, I wanted to offer a perspective – by way of an example – on where I think some of the data technologies we work with could be positioned in terms of relative, high-level characteristics.
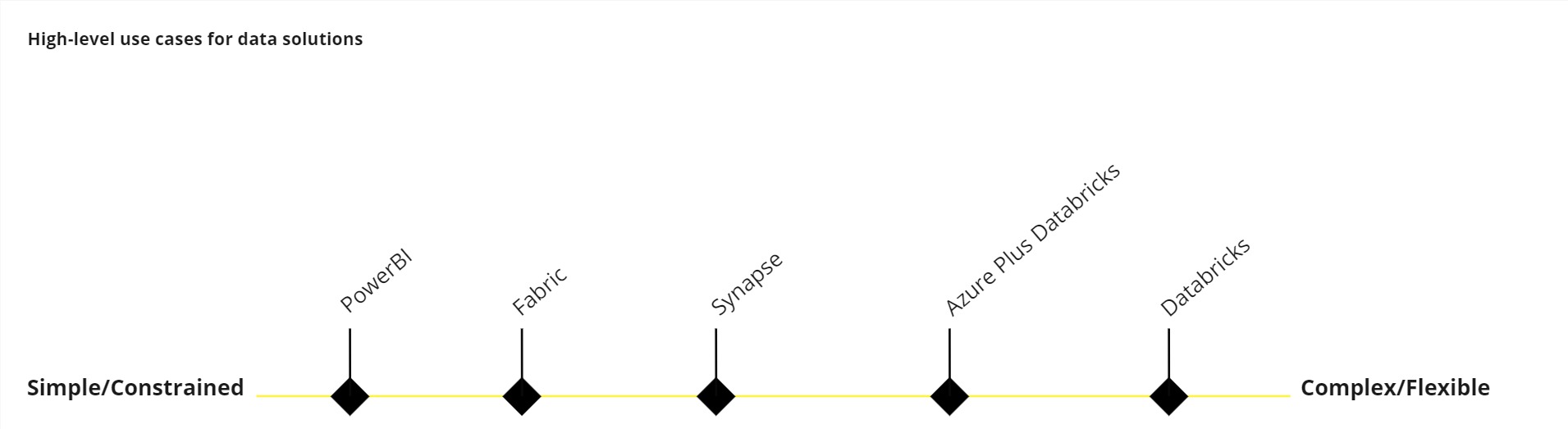
In simple terms, a data solution could be thought of in terms of its suitability to solve different problems on a spectrum, ranging from simple solutions that are often more constrained and opinionated (e.g., a simple Power BI solution with a couple of structured data sources) to much more complex solutions that are typically more flexible (e.g., a big data analytics and machine learning solution using Databricks) that offer greater, fine grained control. I find this can be a helpful way of thinking about problem solving when designing data solutions.
Note; Microsoft Fabric will soon catch up to Synapse in terms of feature set and replace it, but that is an explainer for another blog post.
How technical spikes can help
In my experience, a big problem with ‘some’ architecture functions and architects is designing in isolation from a product or service team and being too far removed from current technology delivery. It is also very difficult, no matter how good someone is, to get everything right up front – continual iteration is required.
However, one thing I emphasise when selecting architecture is the need to run technical spike as part of an evaluation process. You may have narrowed it down to a couple of different technologies and need to put some working theories to the test.
Taking a ‘test the riskiest assumption first’ approach, you can build proof of concepts using different technologies to evaluate their effectiveness, reduce delivery risk, and gain confidence that they will satisfy the requirements you’ve identified.
Technical spikes (or platform and data accelerators for that matter) can be useful for producing solid investment cases and gaining internal buy-in from important stakeholders because you can use the solutions built as demonstrations of the art of the possible with clear pros/cons, business benefits, and budgets for build, run, and support (e.g., it’s easier to estimate work following a technical spike as it allows you to learn more about areas of higher risk and variance).
In depth knowledge of data platforms is required to design the right solution for your needs, but so is a data-first approach
closing thoughts
A lot of organisations still feel the scars of the data warehouse/lake programme that failed badly and cost millions of pounds; however, the technology landscape has evolved quickly of late when it comes to cloud data platforms, consumable AI services, and no/low code. This creates financially viable possibilities because adopting a data platform is no longer the gargantuan effort that it used to be; however, care still needs to be taken to avoid over engineering and solid expertise is needed in the right areas: data platform architecture and configuration.
It is possible to configure Azure – as a data platform – in several ways, supporting simple use cases and more complex services as your needs evolve. A platform like Databricks (grounded in open source/Apache Spark) also aligns well with Azure and offers quite serious ‘big data’ capabilities at scale. In depth knowledge of data platforms is required to design the right solution for your needs, but so is a data-first approach, which when combined with technical spikes and targeted accelerators, can provide you with a data foundation that is appropriately designed, cost effective, and de-risked.
In future blog posts, I’ll do an unboxing of Azure and Databricks data platforms, to look more closely at what their respective strengths are.