data platform series:
Cloud Native Data Platform:
Reference Architecture
Many of our clients come to us as they’re in the early stages of defining their data strategy and need some help defining what technical solution they need. One of the key parts of developing their strategy is showing them a typical reference architecture or blue print for a cloud native data platform. I thought it would be useful to share this example as part of our data platform strategy series.
Whilst every organisation is different and every data solution varies, a lot of value can be gained from utilising a common Cloud Data Platform (CDP) Reference Architecture as a starting point for building internal knowledge and baselining the desired solution.
The six architectural layers
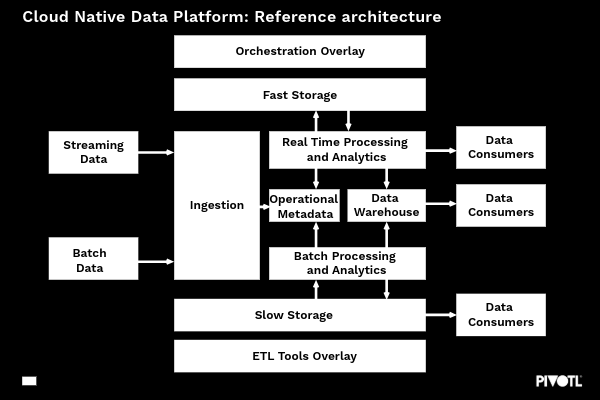
The diagram here shows an extensive, end-to-end reference architecture for a Cloud Data Platform which contains six primary layers – some of which will be relevant to all customers/use cases, and some of which will only be relevant in certain circumstances or use cases, which would be subject to further analysis.

Ingestion Layer
The ingestion layer is responsible for getting data into the platform and differentiates deliberately between batch and streaming data as they are different use cases.
Storage Layer
The Storage layer isolates slow and fast storage due to their characteristics, performance, and cost considerations.
Processing Layer
Services designed to process an abundance of data types – broken down into batch and streaming data (aligned to the ingestion layer)
Metadata Layer
Used to store and organise metadata which drives the operational efficiency of the Cloud Data Platform
Delivery Layer
Along with a Data Warehouse from where data is served, this also includes data consumers, which can be both humans i.e., analysts and other applications.
ETL/Orchestration Layer
Often a combination of tools which provide enhanced functionality from both a business and/or data perspective.
Each layer is a functional component (often consisting of more than one tool/technology) that performs a specific task. Logically, the architecture is Cloud Agnostic but reference implementations exists for each of the major Cloud Providers – Azure, AWS and Google Cloud.
I’ve described each layer in further detail in the following section.
Data ingestion layer
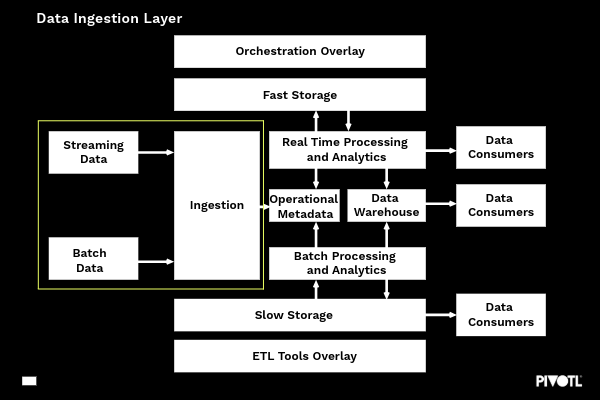
At its simplest, this layer is responsible for getting data out of source systems and bringing them into to the data platform. It does so by ingesting the data into a Data Lake in its original format. Both Batch and Streaming data should be considered first class citizens, although either may be omitted based on the solution and/or desired state.
Capabilities of the ingestion layer primarily focus on:
- Securely connecting to a wide range of data sources on a range of protocols and delivery patterns
- Reliably transporting data into the data lake with no changes. This is vital for scenarios where audit is required or reprocessing may be desirable.
- Populating the metadata layer with MI to ensure downstream processing is as efficient as possible and to facilitate observability of the CDP health
As volumes coming into the platform will often be unknown, it is important for this layer to be highly scalable, modular, extensible and highly available.
STORAGE LAYER
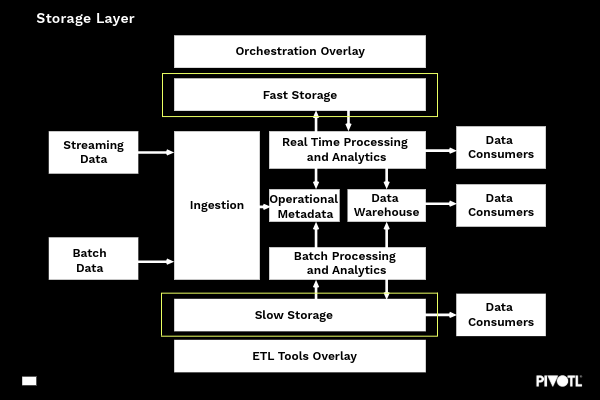
The ingestion layer is responsible for getting data into the platform but does not store any data itself. It is therefore imperative that the Storage Layer provides ample capability to store data as quickly as required and to the volumes necessary – especially as there could be multiple ingestion jobs running concurrently.
Data Storage can be broadly categorised as fast or slow. Fast storage is designed for high frequency, smaller pieces of data – often a few kilobytes or less but with much, much higher performance characteristics. Examples of this might be streaming data coming from millions of IoT devices. Another example of fast storage may be a high capacity message queue.
Slow storage offers a completely different capability set and efficiently handles much larger data sets – from megabytes to petabytes and beyond. The capacity and (often) lifespan of slow data is much higher and the cost typically much lower. An example of slow storage might be a tiered object store.
Capabilities of the storage layer primarily focus on:
- Scalability – handling unknown and logically ‘unlimited’ amounts of data
- Reliability – handling different types of data from different delivery paradigms. Component failure should not affect reliability of the CDP
- Performance – Not just about being ‘fast enough’, performance is about providing the correct tooling and infrastructure for the data required. This will vary based on latency or throughput considerations along with volume and frequency
- Cost Efficiency – When considering large data volumes, cost becomes a key factor. Storing the data as cheaply as possible is a central consideration for almost any client and solution.
processing layer
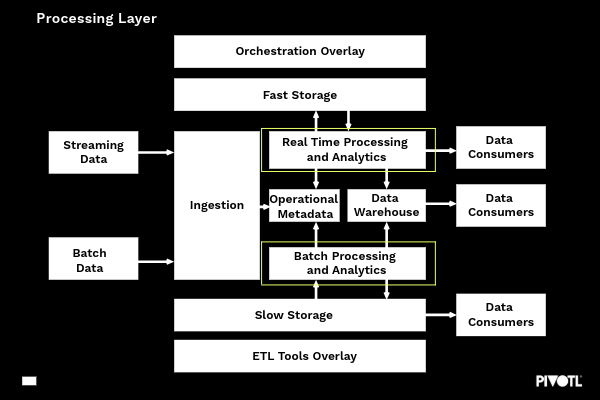
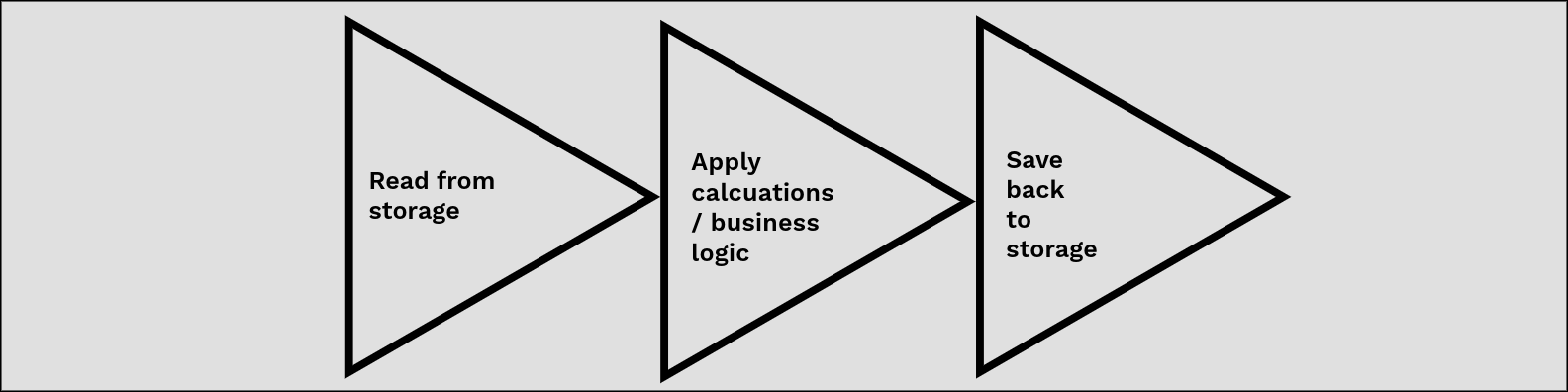
The processing layer is often considered the ‘brain’ of the CDP – this is where business logic is applied, data validation is performed and some transformations take place. This is often (but not always) a three stage process:
Capabilities of the processing layer primarily focus on:
- Support for both batch and real time data
- Provide a programming interface supporting popular languages including C#, Python, Java or no-code, drag and drop style interfaces
- Provide a SQL or SQL-like interface to enable ad-hoc interactions.
Metadata LAYER
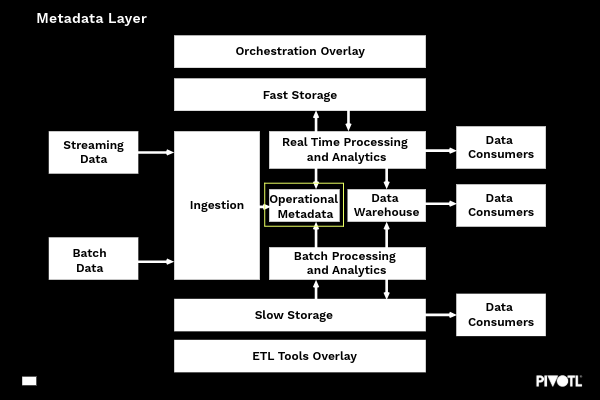
The metadata layer refers to technical or operational metadata, not business or application specific metadata. That is, this metadata provides a store of context and often state that enables the processing layer (and all other layers) to efficiently perform its duties.
Examples of data stored in the metadata layer includes:
- Status of ingestion tasks
- Volumes of data ingested
- Schema information
- Pipeline metadata
- Error information
- Failure rates
- Throughput Information
delivery layer
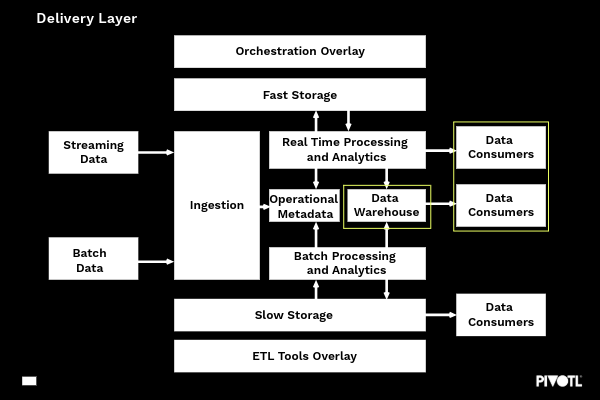
The delivery layer provides a flexible means of getting data to consumers. Some may wish to access data through a SQL interface and query the underlying Data Warehouse, whilst others may wish to consume the data direct from storage. It is the responsibility of the delivery layer to provide these capabilities to ensure consumers can efficiently (and securely) access the data they require.
Capabilities of the ingestion layer primarily focus on:
- Elastic cost model – to be able to scale up or down depending on load/volume. Compute resource may spike during business hours when lots of BI reporting is performed, but be unnecessary when other CDP tasks are running (e.g. overnight ingestion tasks)
- NoOps – there should be little to no tuning or optimisation required beyond those supplied by the cloud vendor.
orchestration LAYER
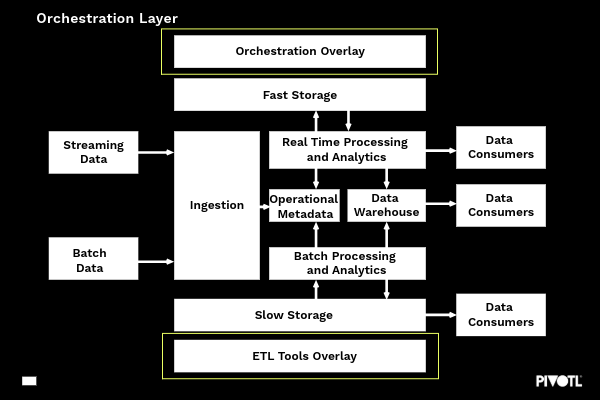
This layer is often a polyglot assortment of tools that may be a combination of custom code, commercial products of service offerings. The orchestration layer is responsible for ordering the processing of jobs – tracking and managing dependency chains, handling errors/retries and ensuring the smooth end to end operation. It is often calling into many of the other layers to perform its role. The ETL layer often provides an interface to define and maintain data pipelines that allows the data to be shared to the business or solution needs.
The ETL layer will also update the metadata layer and in some (simpler) cases, perform the orchestration role too by coordinating multiple jobs.
As I said at the beginning, this is a common reference architecture for a Cloud Native Data Platform but the important part is to ensure that it fits with the needs of your organisation and its Data Strategy. Not all organisations will require the full suite of capabilities outlined.
I have seen huge, costly mistakes made from overtly complex solutions being designed for simple analytics routines, for example. It is about examining your use cases, starting simple and scaling up as needed (evolutionary architecture is highly applicable to data). I will examine and explain how to select the right architecture and solution in the next blog post in our data platform series.